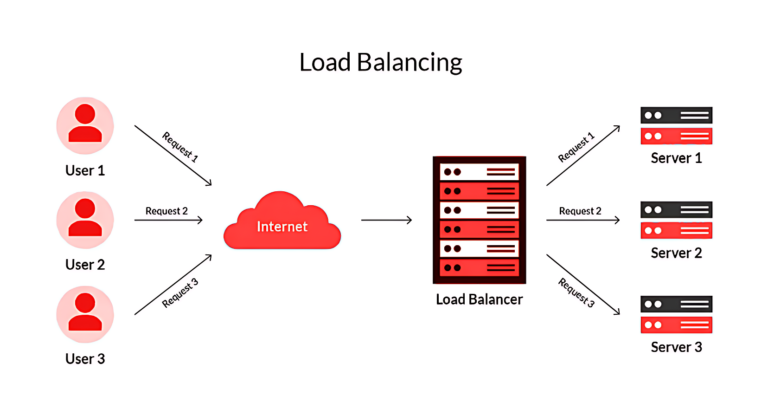
The Role of Load Balancers
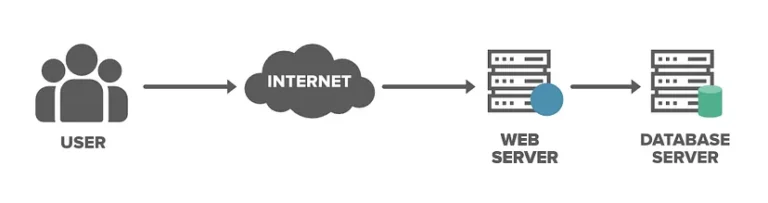
As our user base expands, our application faces higher traffic, increasing the strain on a single server. This surge in concurrent visitors overwhelms the server, seriously impacting the application’s performance.
Traditionally, a lone server managed all traffic. However, at some point, this server would become overwhelmed, struggling to handle all incoming requests on its own.
Here’s the issue with relying on just one server:
- Single Point of Failure: If this server encounters significant problems or crashes completely, the entire application grinds to a halt. Users can’t access it until the issues are resolved, leading to a poor user experience.
- Server Overload: A single web server has limits to the number of requests it can handle. If the business grows and traffic increases, the server becomes bombarded and the application’s performance suffers.
To manage this heavy traffic, we need to scale our system.
Scaling: Vertical and Horizontal
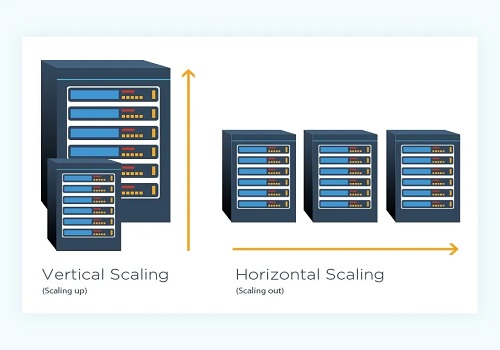
Scaling a system can be approached in two ways:
- Vertical Scaling: This involves adding more resources (CPU/RAM/DISK) to your server.
- Horizontal Scaling: Here, you add more nodes to your existing infrastructure to handle new demands.
We’ll focus on horizontal scalability since, at a certain point, it’s more cost-effective to add more servers than to keep enhancing existing ones.
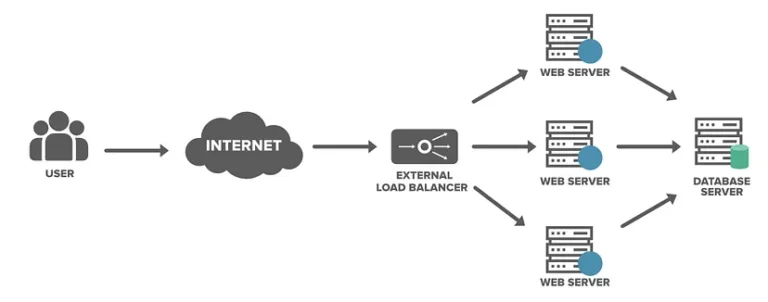
Now that we’ve introduced more servers, the incoming traffic can be distributed among them, ensuring efficient handling of the growing load and faster response times.
How do we decide which server should handle which request?
This is where load balancing steps in.
What is a Load Balancer?
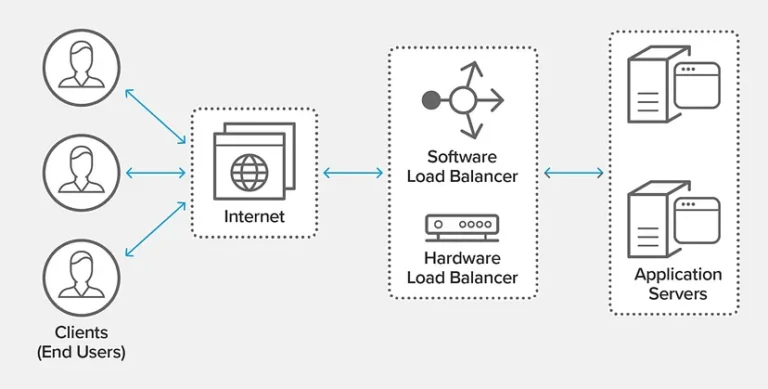
A load balancer evenly allocates the load across multiple servers, enhancing the application’s overall availability and responsiveness. It effectively distributes requested tasks (like database writes or cache queries) among various servers, preventing any one server from getting overwhelmed and degrading the overall performance.
Load balancers enable services to manage countless requests by adding numerous web servers (horizontal scalability). This spreads requests across active servers, so if one server fails, the requests automatically reroute to other active servers.
Placement of Load Balancers
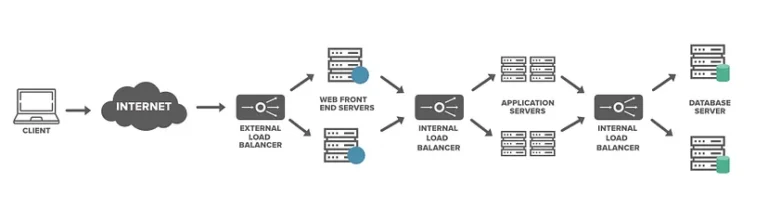
Load balancers are positioned between:
- The client/user and the web server.
- The web server and application servers.
- Application servers and cache servers.
- Cache servers and database servers.
Advantages of Load Balancers
- Users enjoy faster, uninterrupted service.
- Server failures have minimal impact as the load balancer redirects requests to healthy servers.
- Service providers experience less downtime and higher throughput, reducing wait times for users.
- Smart load balancers predict traffic bottlenecks in advance, allowing administrators to take proactive steps.
- The system encounters fewer failures or stressed components, as the load is shared among servers, ensuring they work within their limits.
- However, note that a load balancer could also become a single point of failure.
Load Balancing Strategies
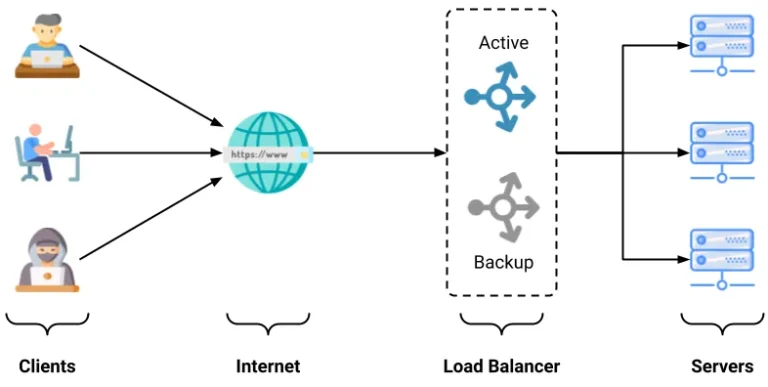
There are two main load balancing configurations:
- Active-Passive: One load balancer distributes traffic, while the other acts as a backup, activated if the active one fails.
- Active-Active: Both load balancers share responsibility for distributing traffic and monitor each other.
Now, how does the load balancer determine which server should handle which request? It’s not a random process; there are load balancing algorithms in play. These algorithms help decide server allocation based on factors like server health, load, and more.
Load Balancing Algorithms
How does the load balancer monitor the servers' status?
Load balancers use the heartbeat protocol to regularly check server health for assigning incoming requests.
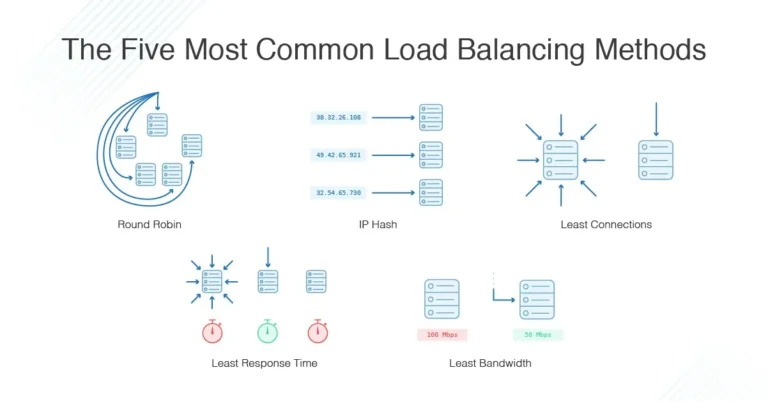
Some common algorithms include:
- Round Robin:
This algorithm works by sequentially sending each incoming request to the next server in line. It’s like taking turns. Once all servers have received a request, the cycle starts again from the first server. Round Robin is simple and ensures that each server gets an equal share of the traffic. However, it doesn’t take server load into consideration.
Example: Let’s say you have three servers A, B, and C. The first request goes to A, the second to B, the third to C, and then it repeats: A, B, C, A, B, C, and so on.
- Weighted Round Robin:
This is an extension of the Round Robin algorithm where each server is assigned a weight representing its capacity or processing power. Servers with higher weights receive a larger proportion of traffic. It’s a way to account for varying server capabilities.
Example: If server A has a weight of 2, server B has a weight of 3, and server C has a weight of 1, the distribution might look like this: A, B, B, C, B, A, B, B, C, and so on.
- Least Connection Method:
With this algorithm, new incoming requests are sent to the server that currently has the fewest active connections. This helps distribute the load more evenly based on actual server load.
Example: If server A has 10 active connections, server B has 8, and server C has 5, the next request would be sent to server C.
- Least Response Time Method:
In this algorithm, the incoming request is sent to the server that has the lowest response time, i.e., the server that can handle requests more quickly. This helps ensure that users are directed to the server that is currently performing the best.
Example: If server A has a response time of 20ms, server B has 15ms, and server C has 25ms, the next request would be sent to server B.
- Source IP Hash:
This algorithm involves hashing the source IP address of the incoming request to determine which server to send it to. The goal is to ensure that requests from the same source IP are consistently routed to the same server. This can be useful for maintaining session persistence.
Example: If the source IP address of a request hashes to a value that corresponds to server B, all subsequent requests from that same source IP would be sent to server B.
"A load balancer facilitates dynamic scalability of the application, leading to significant enhancements in system performance, resilience, and throughput."
Liked the content? Fuel my passion with your support! 😇
